스프링 DB-JDBC
스프링 DB
서버에서 중요한 데이터들은 DB에 보관하는 것이 기본이다.
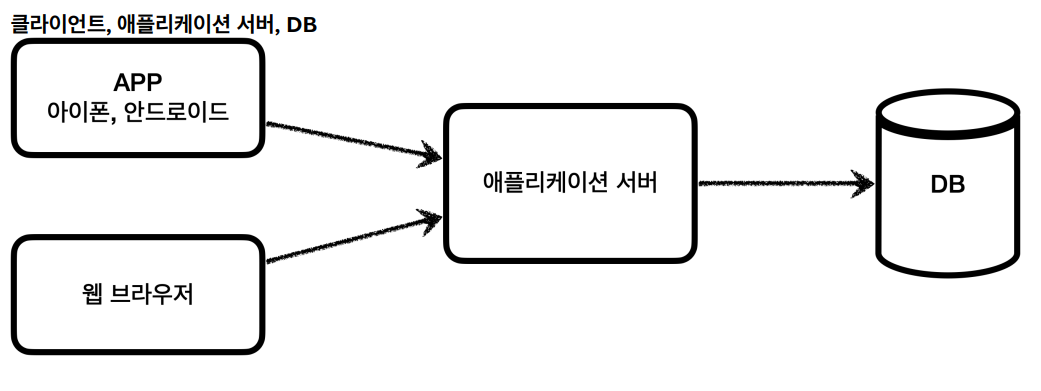
어플리케이션, 브라우저에서 서버에 데이터를 조회하거나 등록하면,
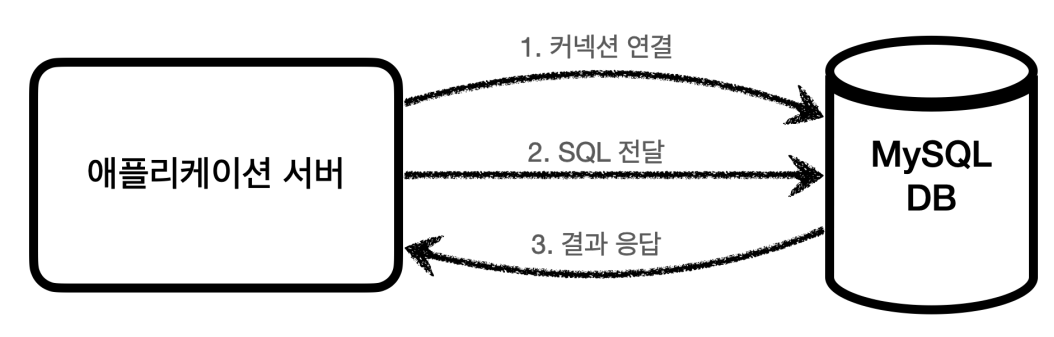
위와 같이 DB와 커넥션을 연결하고 SQL문을 보내 원하는 쿼리를 전달한다. 그 후 서버는 DB의 응답을 받고 이를 이용하여 클라이언트에 응답을 보낸다.
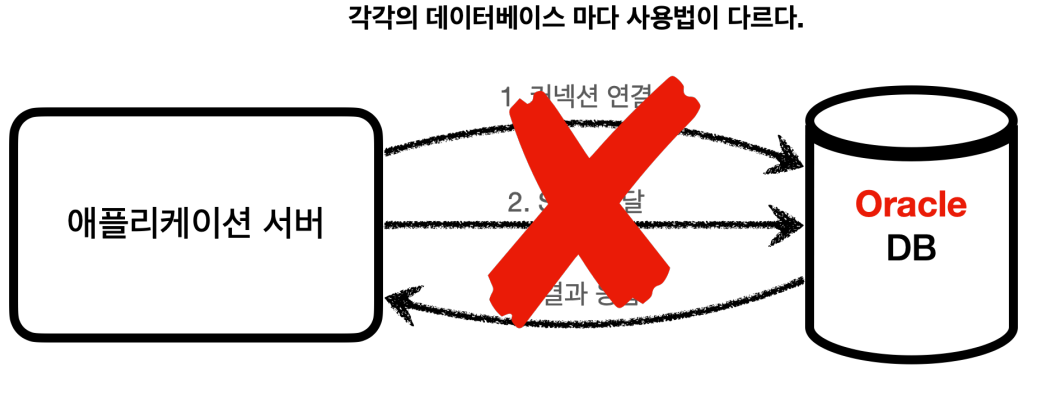
그런데 문제는 DB마다 커넥션을 연결하는 방법, SQL을 전달하는 방법, 결과를 응답받는 방법 등 모든게 세세하게 다르다는 것이다.
이로 인해 DB를 다른 종류의 DB로 변경하면 서버의 DB 사용 코드도 모두 변경해주어야 하고, 개발자가 새로운 DB의 사용방법을 처음부터 학습해야 하는 문제가 발생한다.
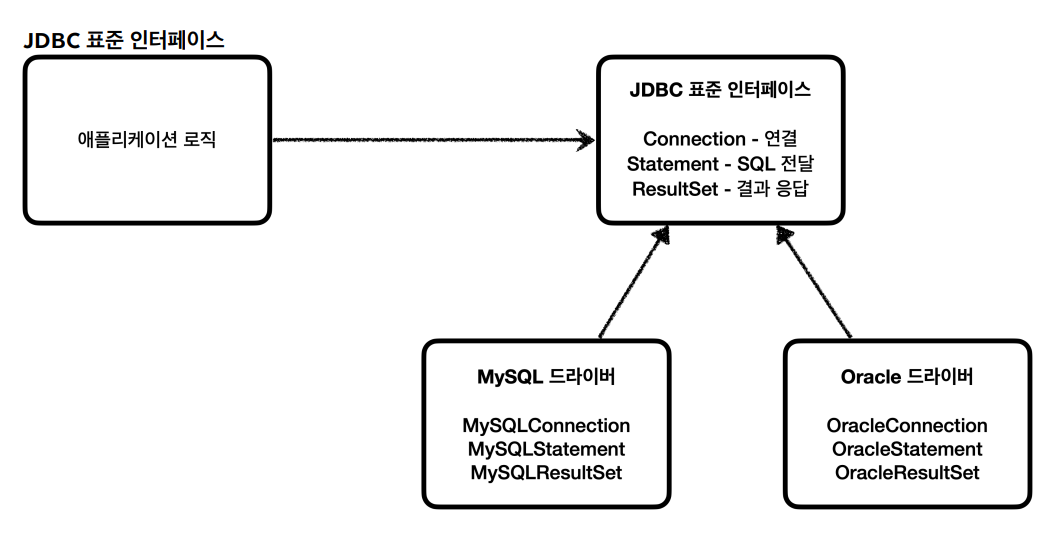
이런 문제를 해결하기 위해 나온 것이 JDBC이다. JDBC는 자바에서 DB에 접속할 수 있도록 하는 자바 API이다. 표준 인터페이스로 연결, SQL을 담은 요청, SQL에 대한 응답을 정의하였다.
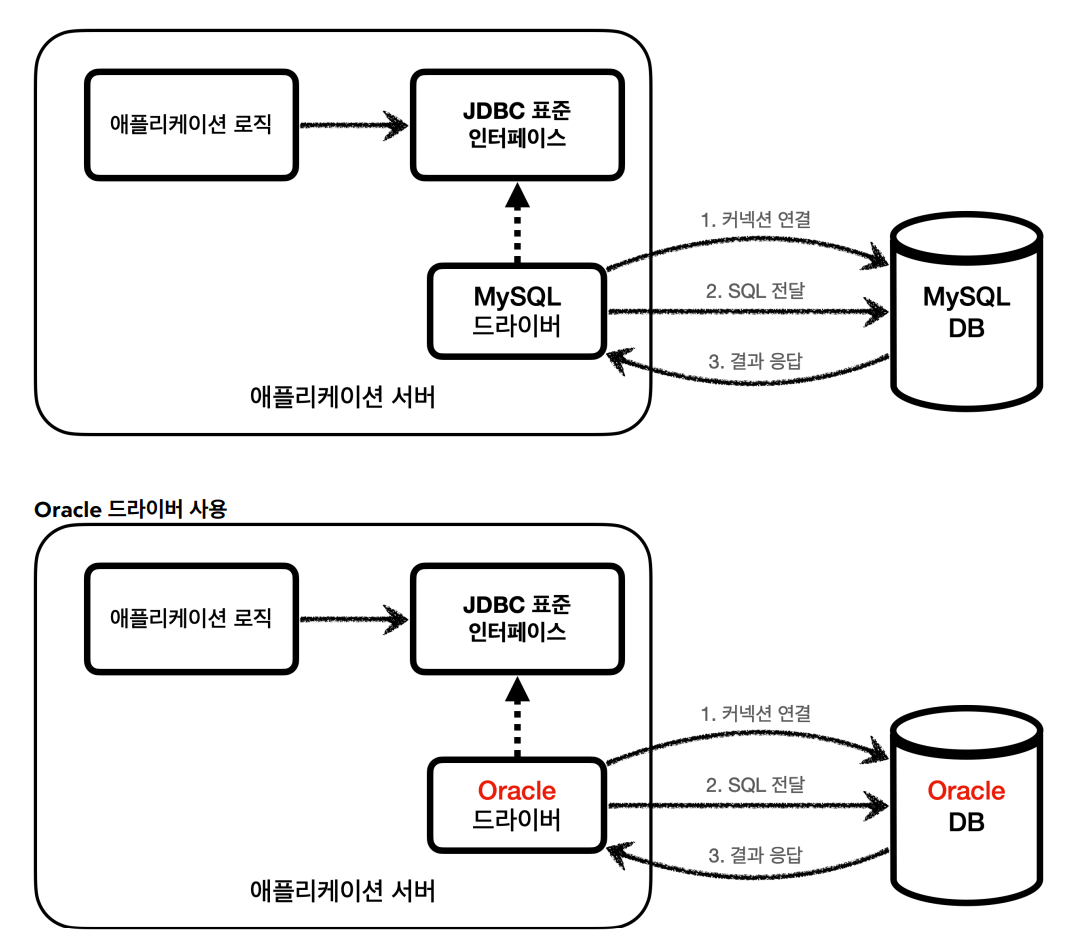
각 DB는 JDBC 인터페이스를 자신의 DB에 맞게 구현한 드라이버를 지원한다. 이제 개발자는 JDBC만 배워서 사용하면 드라이버가 있는 DB는 모두 사용할 수 있게 된다.
또한 서버에서 사용하던 DB를 교체하더라도 우리는 해당 DB가 아닌 JDBC를 사용중이므로 코드를 수정할 필요가 없어진다.
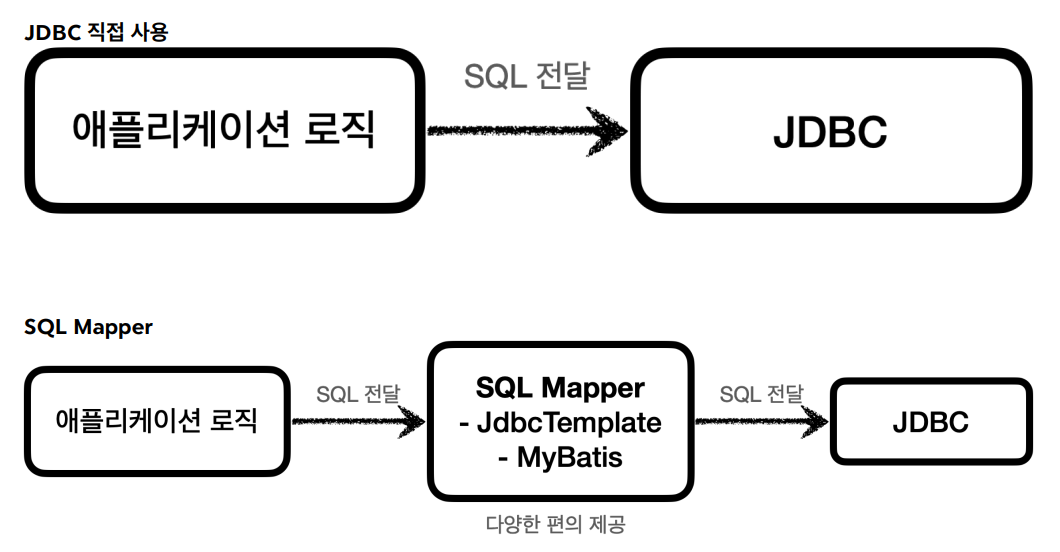
JDBC는 1997년 출시된 오래된 기술이므로, 지금은 JDBC를 직접 사용하기보단 JDBC를 편리하게 사용하는 여러 기술들을 사용한다.
대표적으로 JDBCTemplate,MyBatis 등의 SQLMapper와 Hybernate, JPA 등의 ORM 기술이 있다.
SQLMapper는 SQL만 알고 있다면 SQL을 각 DB에 맞게 변환해주고, 응답 결과를 객체로 편리하게 변환해준다. 하지만 개발자가 SQL을 입력해야 한다는 단점이 있다.
ORM 기술은 스프링에서 객체를 주입하듯이 사용하면 내부에서 SQL을 동적으로 생성해주고, DB마다 다른 SQL을 사용하는 문제도 해결해준다. 하지만 ORM 기술 자체의 난이도가 있어 깊이있는 학습이 필요하다.
DB 커넥션
일단 JDBC를 사용하여 스프링과 DB를 연결해보자. DB와 연결하는 방법으로는 JDBC의 DriverManager를 사용하는 방식과, 이후 설명할 커넥션 풀을 사용하는 방식이 있다.
아래 예제는 DriverManger를 사용하여 연결한 뒤 Connection 객체를 반환하는 메서드이다.
public static Connection getConnection() {
try {
Connection connection = DriverManager.getConnection(URL, USERNAME, PASSWORD);
log.info("connection={}, class={}",connection, connection.getClass());
return connection;
} catch (SQLException e) {
throw new IllegalStateException(e);
}
}DriverManager의 getConnection() 메서드를 통해 연결하고, Connection 객체를 반환한다. SQLException을 처리해주어야 하므로 try-catch문으로 감싸주었다.
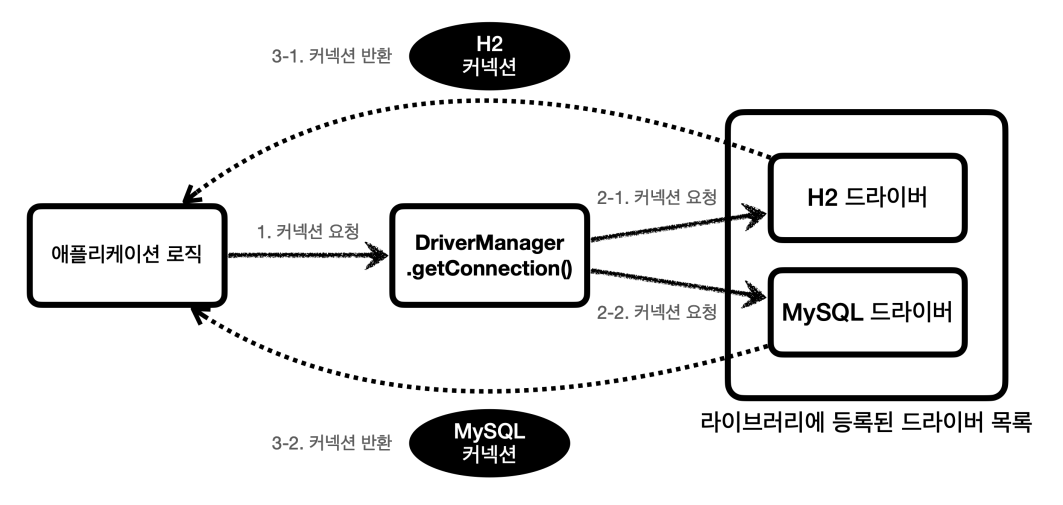
DriverManager의 작동 방식은 위 그림과 같다. DriverManager가 라이브러리에 등록된 드라이버들을 인식하고, 순서대로 URL과 추가 정보들을 넘겨 해당 드라이버가 처리할 수 있는지 확인한다.
처리할 수 있는 요청이라면 해당 DB와 연결을 실행하고 Connection 객체를 반환한다. 없다면 다음 드라이버에 순서가 넘어간다. 위 예제에서는 h2 드라이버만 라이브러리에 등록했기 때문에 h2 데이터베이스와 연결된다.
JDBC 사용
JDBC를 사용하여 회원의 CRUD를 실행하는 예제를 구현하였다. 모든 코드를 올리기엔 양이 많으므로 중요한 코드 한 파트만 확인해보자. 아래 코드와 여타 저장, 수정 등은 모두 형식이 매우 유사하므로 형식을 중심으로 보자.
public Member findById(String memberId) throws SQLException {
String sql="select * from member where member_id=?";
Connection con=null;
PreparedStatement pstmt=null;
ResultSet rs=null;
try {
con=getConnection();
pstmt=con.prepareStatement(sql);
pstmt.setString(1,memberId);
rs = pstmt.executeQuery();
if(rs.next()) {
Member member=new Member();
member.setMemberId(rs.getString("member_id"));
member.setMoney(rs.getInt("money"));
return member;
}
else {
throw new NoSuchElementException("member not found memberId="+ memberId);
}
} catch (SQLException e) {
log.error("error",e);
throw e;
} finally {
close(con,pstmt,rs);
}
}member_id를 통해 DB에서 데이터를 조회하는 메서드의 코드이다. SQLException의 처리가 필요하므로 try-catch 문으로 감싸주었고 예외는 그냥 메서드 밖으로 던져주었다.
PreparedStatement는 DB에 전달할 SQL와 파라미터값을 준비한다. pstmt의 setString(), setInt() 등의 메서드를 사용하여 파라미터 값을 입력하면 SQL injection 문제를 막을 수 있다. 이에 대해 설명하면 너무 길어지므로 따로 알아보자. pstmt에 필요한 데이터를 모두 입력했다면 데이터를 변경하는지, 조회하는지에 따라 executeUpdate(), executeQuery() 등의 메서드를 사용하여 SQL을 DB로 던져줘야 한다.
ResultSet은 select 쿼리 등으로 반환받은 결과값이 들어오는 객체이다. 사용 방식이 여타 Collections와 달리 조금 특이한데 아래 그림을 확인하자.
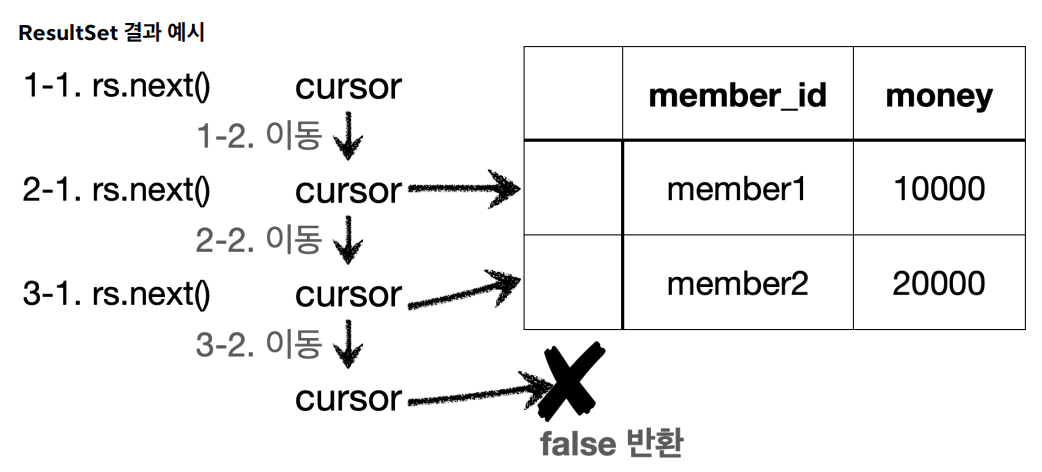
ResultSet은 내부의 cursor를 사용하여 데이터를 조회한다. 최초의 커서는 데이터를 가리키고 있지 않기 때문에 rs.next() 메서드를 한번은 호출해야 데이터를 조회할 수 있다.
rs.getString(“member_id”) 는 현재 커서가 가리키는 데이터의 member_id 데이터를 String 타입으로 반환받겠다는 뜻이다. 이와 같이 getString(), getInt() 등의 메서드로 데이터를 조회할 수 있다.
Connection을 사용하여 원하는 로직을 실행했다면 꼭 리소스를 정리해주어야 한다. con, pstmt, rs 모두 close() 메서드를 통해 리소스를 정리할 수 있는데 리소스를 정리하지 않으면 연결이 계속해서 유지되어 리소스를 소모하는 리소스 누수를 발생시킨다.
정리
JDBC의 탄생 배경을 배우고 JDBC를 사용하여 스프링과 DB를 연결하고 사용하는 예제를 구현하였다. 상위 기술인 SQLMapper와 ORM 기술이 모두 바탕으로 JDBC를 사용하므로 작동 원리를 배우고 넘어가는 것은 확실히 좋은 것 같다.
다음 포스팅에서는 커넥션 풀과 데이터 소스에 대해 알아보도록 하겠다.