SSAFY 공통 프로젝트 회고
공통 프로젝트 끝
다사다난했던 공통 프로젝트가 끝이 났다. 하면서 얻은 것, 느낀 것을 하나씩 정리해보려 한다.
얻은 것들
Jira
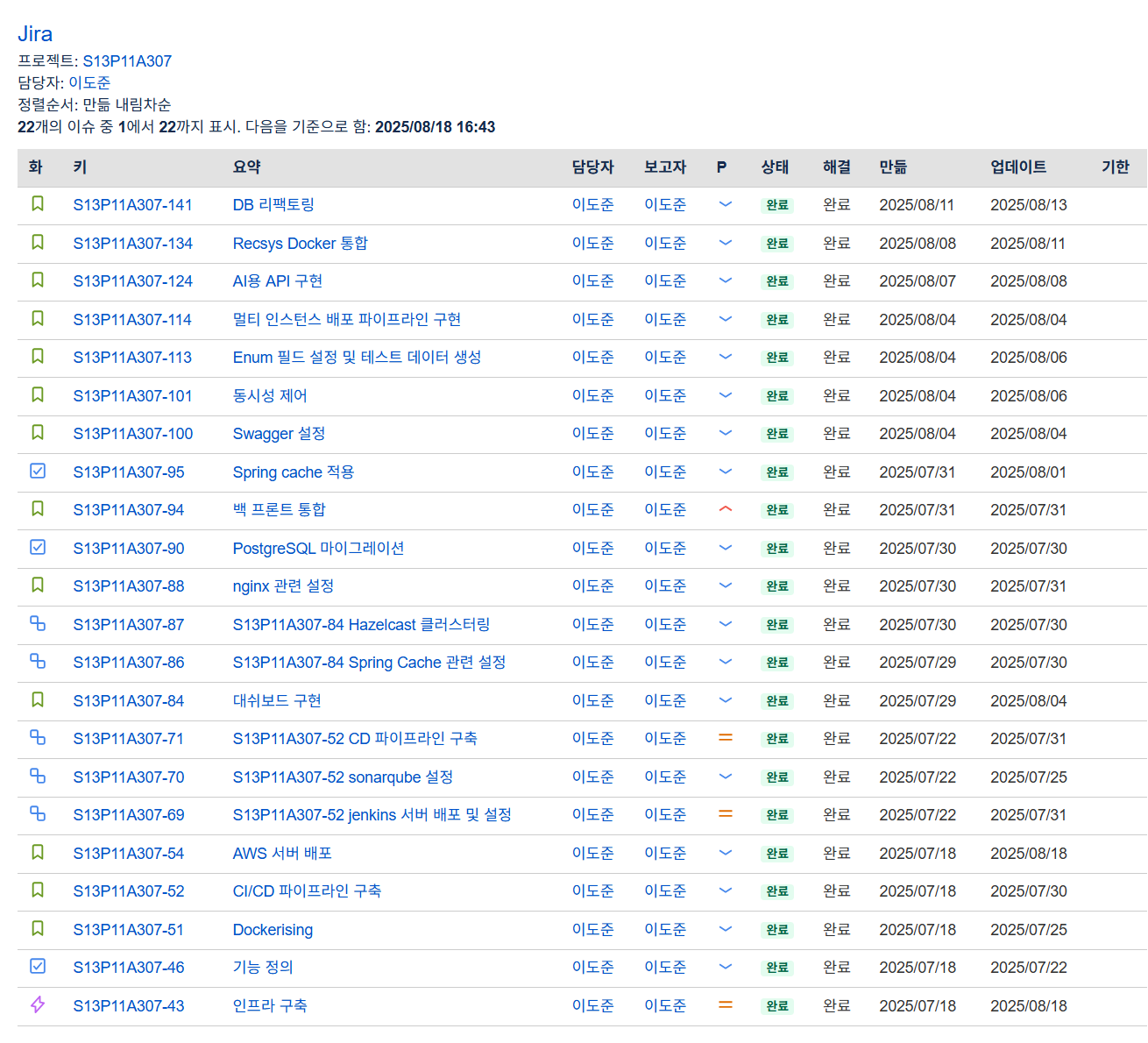
처음으로 써본 Jira지만 나름 열심히 썼다. story 별, task 별 컨벤션도 따로 만들어서 티켓 만들 때 컨벤션대로 작성하라고 팀원들도 독려하고 작업을 하기 전에는 너무 사소한 작업만 아니면 무조건 티켓을 만든 후에 작업을 하도록 컨벤션을 정했다.
처음에는 작업에 쓸 시간이 Jira 작성에 뺏기는 것 같아 좀 아쉬웠지만 지날수록 왜 Jira를 실무에서 사용하는 지 알 것 같았다. 다른 팀원들이 어떤 작업을 하고 있는지, 어떤 작업이 밀려있는지, 어디에 막혀있는지 등등을 한 눈에 볼 수 있었고, 무엇보다 가장 큰 것은 화면을 띄워놓고 ‘이제 뭐해야되더라’ 하는 시간이 획기적으로 줄어들었다.
추후 리팩토링 할 부분을 발견해도 Jira에 바로 티켓으로 적어두니 까먹고 수정하지 않는 일도 거의 일어나지 않았다. 지금 이 회고를 쓰는 데에도 내가 뭘 했는지가 다 기록이 되니 큰 도움을 받고 있다. notion보다도 훨씬 개발에 친화적이고 나중에 프로젝트 할 때에도 적극적으로 사용해보면 좋을 것 같다. 프로젝트 막바지에 너무너무 급해서 Jira를 일주일 가량 못 쓴건 조금 아쉬운 부분이다.
분산 환경 관리
사실 이전 프로젝트에서는 분산 환경을 구성까지만 하고 프로젝트가 끝나버려서 제대로 분산 환경을 활용해보지 못했다. 방학 때 하려다가 역시 방학이라 그런가 흐지부지 돼버렸다. 이번 기회에 평소 해보고 싶었던 동시성 제어를 공부하고 적용해봤는데 역시 고려할 게 많았다.
락을 걸어서 임계영역을 만드는 건 알고 있었지만 락을 인스턴스끼리 공유할 수 있도록 Redis, Hazelcast같은 외부 서비스가 필요한 것은 몰랐다. 작업 도중 스레드가 멈추거나 하면 해당 작업 바깥의 나머지 작업들이 계속 진행되지 않도록 thread.inturrupt() 메서드로 인터럽트 예외를 반환해주는 공정도 이번에 처음 알았다.
다행히 설정한 분산 락과 분산 캐시는 모두 잘 작동하여 동시성 테스트도 무사히 통과하고 캐싱을 통해 응답시간도 획기적으로 줄일 수 있었다.
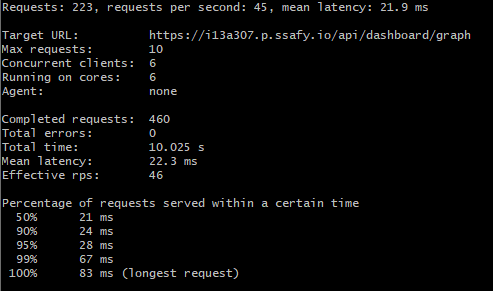
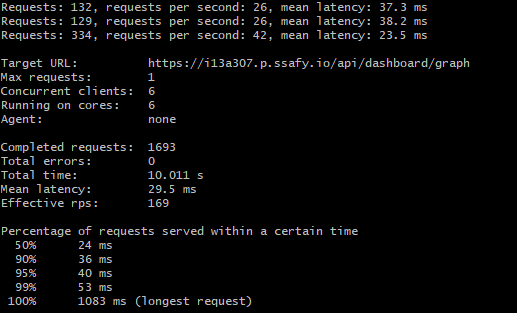
(첫 캐시미스에서 1083ms던 응답시간이 이후 캐시히트부턴 평균 30ms로 97%가량 응답시간이 줄어든 모습)
다음 프로젝트에서는 MQ, Redis를 활용해서 좀 더 깊이있는 분산 환경 제어를 해보면 좋을 것 같다.
Jenkins & Sonarqube
이전 프로젝트에서는 Github와 호환이 잘되는 Github action을 통해 CI/CD 파이프라인을 구성했었는데, 이번엔 Gitlab을 사용하게 되면서 사용하기가 좀 애매해졌다. 애초에 쓸 수 있는지도 잘 모르겠다.
그래서 대안으로 떠오른게 Github action과 비슷한 사용방법을 가진 것으로 보이는 Gitlab runner와, 실무에서 많이 사용되는 Jenkins였다. 결과적으로 러닝커브가 조금 있어도 실무에 많이 사용되고 생태계가 강력한 Jenkins를 사용하기로 결정했다. Jenkins를 사용하며 느낀 점은 Github action보다 훨씬 기능이 많고 사용자가 자유롭고, 그만큼 설정해줘야 하는 것도 많다는 것이었다. 하지만 어느정도 배우고 나니 플로우 자체는 이전 Github action을 사용했던 것과 비슷하게
Docker 빌드 -> 이미지를 Docker hub에 push -> 서버에 접속 후 이미지를 pull해와 사용
과 같은 플로우로 흘러갔다. 뭔가 저번이랑 똑같고 심심한 느낌이라 Jenkins의 강력한 플러그인 생태계도 사용해 볼 겸 나름의 킥으로 넣은게 Sonarqube다. 코드 품질을 관리해서 좋은 코드를 짤 수 있도록 도와주는 툴이라고 들었는데, 사실 아직도 기본적인 메서드 추출, 재사용 가능한 모듈화된 코드 만들기 등의 기본적인 부분은 알지만 ‘그래서 좋은 코드란 어떤 코드에요?’ 라고 물으면 확실하게 대답할 수 있을 것 같지 않았다. 그래서 이번 기회에 Sonarqube를 Jenkins와 통합해서 사용하며 코드를 관리하면 좋겠다고 생각했고 통합 과정을 마치고 화면을 보니 상당히 체계적으로 잘 나왔다.
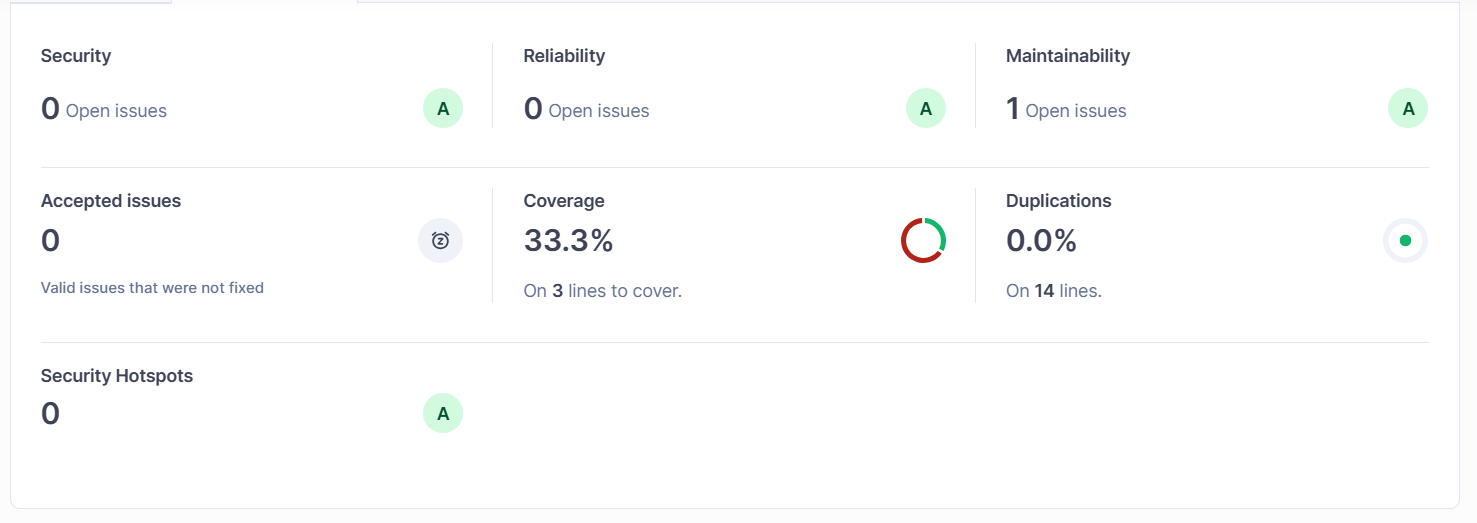
코드 중복, 테스트 커버리지, 보안 이슈, 코드 지속가능성에 영향을 주는 기술 부채 등을 한 화면에서 볼 수 있도록 표시해주는 것을 볼 수 있다. Jenkins와 통합이 끝났기 때문에 앞으로 merge 되는 코드들의 Sonarqube 결과를 보고 문제되는 부분을 고치고, 커버리지를 60~70프로 이상으로 항시 유지하고, 중복되는 부분은 추출해서 사용함으로써 코드 중복을 줄이고 등등… 하면 정말정말 좋겠다고 생각을 했었다.
근데 개발이 기능 구현도 급급한 상황까지 가버리다 보니 거의 방치되다시피 해버린게 아쉬움으로 남는다. 다음 프로젝트에서 좀 더 여유가 있는 팀원들을 만난다면 제대로 한번 활용을 해보고 싶다.
PostgerSQL
사실 이건 썼다고 하긴 뭐하다. 원래는 PostgreSQL이 지원하는 Full Text Scan 기능을 사용해서 검색 기능을 날먹하면 좋겠다고 생각해서 도입한거였는데, 그게 후순위로 밀리면서 결국 프로젝트 끝날 때까지 못하게 됬다.
하지만 도입함으로써 얻은게 없지는 않았는데, 먼저 Spring JPA의 강력함을 다시 한번 느끼게 됬다. 로컬 환경에서의 H2, 서버에서 사용하던 MySQL, 마이그레이션한 PostgreSQL을 오가면서도 백엔드 단에서는 코드 수정이 네이티브 쿼리 몇 줄을 제외하곤 거의 없었던 부분이 JPA의 강력한 추상화를 실감하게 해줬다.
두 번째로는 Json 타입 컬럼이 이제 상당히 기술적으로 유용한 수준까지 올라왔다는 것을 알게됬다. Enum 타입의 필드를 @ElementCollection으로 관리하다가 이후 DB 튜닝을 할 때 DTO 프로젝션이 복잡해져 골머리를 썩을 때 조사를 하다 알게 된 사실이다. PostgreSQL 최신 버전에서는 JSON 타입 컬럼에 대해 집계 함수 등의 기능이 늘었고, 속도도 Enum 테이블을 join하는 것보다 훨씬 빠르다는 것이다. Enum의 경우 상수고 singleton이기 때문에 일반 string에 비해 속도에 이점이 있다고는 하지만 DB에서 Join이 필요한 점을 감안하면 역시 Json 컬럼이 훨씬 빠르지 않을까 생각하지만 이 부분은 조사가 더 필요할 것 같다. 하지만 이렇게 Json 컬럼을 사용할 경우 DB가 종속되어버리는 것은 트레이드 오프인 것 같다.
기타
이외에도 Enum 컬렉션 필드 때문에 DTO 프로젝션이 잘 안되 DB 엔티티 통째로 가져오는걸 네이티브 쿼리를 사용해서 리팩토링 한 것, RestTemplate을 사용해서 외부 api와 통신한 것, 여러 api를 작성한 것 등등이 있지만 너무 소소한 것 같아 따로 적지는 않겠다. 그래도 예상보다는 완성도가 높게 됬고 얻은 것도 꽤 있던 프로젝트였다.