기술적 고민
서론
이번에는 프로젝트를 하면서 생긴 기술적 고민들에 대한 내용과 내가 도출해낸 솔루션을 정리해보려 한다.
고민들
Gitlab runner VS Jenkins
CI/CD 파이프라인을 구축하는데 있어 이번엔 플랫폼이 Github가 아닌 Gitlab을 사용하기 때문에 이전에 CI/CD에 사용했던 Github action을 사용하지 못하게 되었다.
후보군은 SSAFY 측에서 권장하고 실무에서도 많이 사용되는 Jenkins와 이전에 사용했던 Github action과 사용법이 비슷해보여 쉽게 적용할 수 있을 듯한 Gitlab runner 두 가지로 좁혀졌다.
선택은 기술 스택을 늘릴 수 있고, 무엇보다 실무에서도 많이 사용되며, 환경과 생태계가 강력한 Jenkins를 채택했다. 다른 것보다 이전에 했던걸 또 하는 것보단 조금 도전적인걸 원하기도 했다.
개인적인 사용 소감으로는 Github action보다 훨씬 강력하고 자유롭고, 그만큼 사용자의 책임도 늘어났다. Freestyle job으로 어떻게든 shell script를 안쓰고 해보려 했지만 시간만 버렸다. 스크립트가 결국 제일 안정적이고 직관적이다.
서버 관련 문제
SSAFY 측에서 제공받은 서버의 스펙은 다음과 같다.
2.30GHz 4코어 cpu, 16gb ram, ssd 300gb
서버가 하나라서 Jenkins, sonarqube 서버도 분리가 안되고, DB 서버도 분리가 안되서 한정된 자원 내에서 어떻게 사용해야 할지 고민을 좀 했다.
- 현재 Jenkins와 Sonarqube가 어플리케이션과 같은 서버를 공유하는 문제
이러면 어플리케이션과 CI/CD 툴이 자원을 경합하는 문제가 있는건 물론이고, 서버가 다운되면 재배포 해야 할 툴도 같이 다운되버리는 치명적인 문제가 있다. 보안 상으로도 좋지 않다.
왠만하면 이렇게 관심사가 다른 프로세스끼리 자원을 경합하는 것을 좋아하지 않는데 아무튼 내 돈은 쓰기 싫고 지급받은 건 ubuntu 서버 한 대 뿐이니 어쩔 수 없다.
확인해 본 결과 현재 16gb 메모리에서 Jenkins+Sonarqube 서버를 띄워놓는 것만으로 4.4gb를 점유하고 있었다.
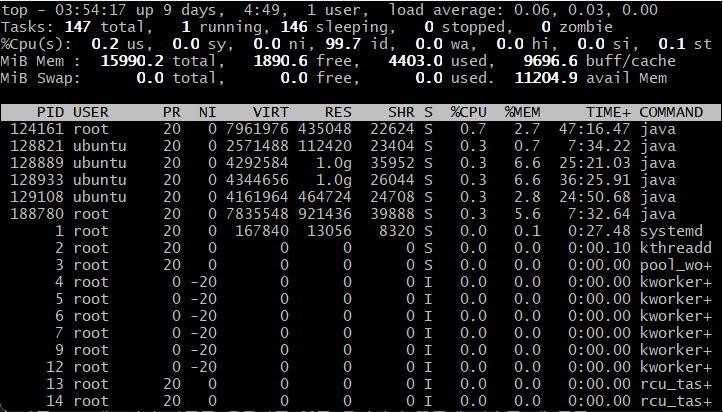
빌드나 코드 테스트 과정을 실행 중이지 않음에도 이 정도면 분명 빌드 등의 과정이 돌아가면 추가로 자원을 점유할테고, 그것은 어플리케이션이 사용할 자원이 더 줄어드는 것을 의미한다.
어떻게 할 지 생각해봤는데 배포 이후엔 심야 2시 이후 자동으로 build를 하는 nightly build 방식을 채택하기로 했다.
일단 서버를 분리할 수 없는게 가장 크고, CI/CD 툴에 메모리 제한을 둬도 좋겠지만 그냥 서로 자원을 점유하는 시간을 분리하는게 낫겠다고 판단했다. 현재는 개발 과정이기 때문에 build가 잦지만 배포 이후에는 크게 지금 당장 build해야 하는 경우는 적을 것이라 판단했기에 이 방안을 채택했다.
- DB 문제
DB 서버가 분리가 안되는 이상 Docker compose에서 같이 컨테이너화 시켜서 올릴 것 같은데, 한번 써보고 싶었던 PostgreSQL이 기존에 사용하던 MySQL에 비해 메모리를 확실하게 많이 잡아먹다 보니 써도 될지 고민을 좀 했다.
이런 저런 자료를 확인하고 현재 우리 프로젝트의 상황을 고려한 결과 특정한 사용자 풀을 대상으로 한 소규모 서비스이기 때문에 최대 연결 수가 그리 크지 않을 것이고, 어플리케이션 컨테이너를 3개 띄우는 상황을 가정해도 OOM 문제가 일어날 것 같지는 않다고 판단해서 PostgreSQL을 사용해보기로 했다. PostgreSQL이 제공하는 Full text scan 기능이 현재 프로젝트에서 꽤 매력적으로 느껴지기도 해서 그렇게 결정했다.
대시보드 관련 문제
프로젝트에서 현재 사용자 관련 정보를 한 눈에 확인할 수 있는 대시보드 기능이 필요해서 구현하게 됬는데, 어떤 식으로 구현할 지가 고민이었다. 기획이 명확하지 않아 기획을 겸하면서 구현한 것도 있고, 프론트에게 데이터를 어떻게 던져줘야 잘 받아서 대시보드를 구현할 지도 고민이었다.
나름 합리적이라 판단되는 방식으로 API를 만들고, 대시보드 기능 같은 경우엔 대규모 데이터 처리가 이루어지면서도 많은 사람들에게 공개되는 정보이기 때문에 어떻게 효율적으로 처리할 수 있을까를 고민했다.
처음에는 DB의 인덱싱을 생각했지만, 실시간 정합성이 크게 중요하지 않은 기능이라 판단해서 캐싱으로 선회했다. 5분 가량 주기의 shorttermcache를 만들어서 사용하면 적절할 것이라 판단했다.
그런데 캐싱을 사용하기로 결정하자 바로 아래의 문제로 이어졌다.
캐시 클러스터링 문제
사실 소규모 서비스이기 때문에 어플리케이션을 여러 개 작동시킬 필요는 없지만, 만약의 경우 예기치 못한 문제로 어플리케이션 하나가 다운됬을 때를 대비해서, 그리고 이후의 무중단 배포 등의 확장까지 생각해서 어플리케이션 컨테이너를 3개 정도 두고 Nginx로 로드밸런싱을 하기로 했다.
그러자 이제 인스턴스가 달라도 같은 캐시를 사용하도록 캐시 클러스터링을 해줄 필요가 생겼는데, 캐시 자체를 스프링에서 사용해본게 처음이라 이 부분도 공부가 필요했다.
Redis 같은 경우는 실무에서도 많이 쓰이고 강력한 기능과 생태계를 자랑하는 인기있는 기술이지만, 서버를 따로 둬야 하고 설정도 복잡해서 안그래도 메모리에 허덕이고 있는데다 소규모 서비스인 지금의 프로젝트에는 과하고 어울리지 않는다 판단했다.
그 대안으로 사용한 것이 오픈소스 라이브러리인 HazelCast인데, gradle 의존성 추가로 편리하게 사용이 가능하고 Spring Cache와 손쉽게 연동이 가능해서 채택했다.
HazelCast의 경우 따로 서버를 설치하지 않고 gradle 의존성으로 사용하면 embedded 방식으로 작동하는데, 각 인스턴스의 JVM 안에서 노드를 만들어 작동하고 멀티캐스트, 또는 TCP/IP로 각 노드끼리 통신하여 데이터를 분산, 클러스터링 한다.
이 과정에서 JVM 내의 힙 메모리를 사용하지만, Hazelcast 자체의 오버헤드와 캐시 데이터 크기를 고려해도 크게 영향이 없는 수준이라 판단했다. 노드 간 통신은 TCP/IP로 진행하는데 컨테이너 네트워크를 사용하기 때문에 더 편리하게 통신할 수 있었다.
— 25.08.18 수정
사용 결과는 득도 있고 실도 있었다. 먼저 비주류 기술이다 보니 Redis에 비해 압도적으로 정보량이 적었고, 사용의 어려움을 초래했다. 그리고 Redis는 주류 기술인 이유가 있었다. 분산 캐싱과 락, 이외에도 여러 강력한 기능을 제공했고 내 서버의 컨테이너 한 칸을 주기에 충분한 기술이었다.
하지만 역시 러닝커브가 있었고 Hazelcast를 선택한 건 꽤 합리적인 선택이었다고 생각한다. 성능 개선은 꽤 놀라웠다.
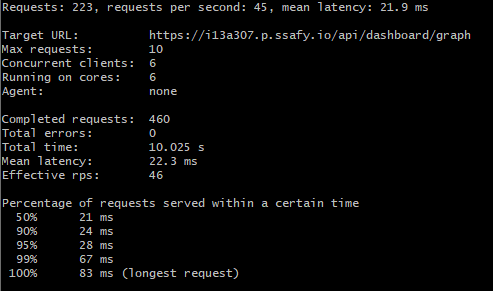
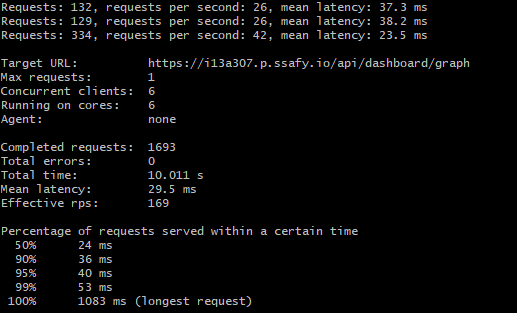
loadtest로 스크리닝 해본 결과 기존에는 1082ms까지 걸리던 요청이 캐시 히트 이후부턴 평균 30ms 정도를 유지하여 97%가량의 성능 향상을 보였다. Redis의 경우 아마 컨테이너를 따로 쓰다보니 네트워크 지연이 있을 듯 한데 현재의 Hazelcast 노드도 JVM 내부에 있지만 TCP/IP로 노드끼리 통신하다 보니 네트워크 지연은 똑같지 않을까 싶다. 그냥 Redis 쓸걸.
Sonarqube 관련 문제
사실 Sonarqube를 쓰게 된 이유는 별게 없다. Jenkins가 기존에 사용하던 Github action과 다르게 지원하는 강력한 생태계 기능들을 살펴보던 중 Sonarqube라는 코드 품질 분석 서비스가 있는 것을 발견했다. Jenkins의 기능을 시험할 겸, 그리고 사실 아직 품질 높은 코드라는 게 뭔지 잘 모르기 때문에 Sonarqube가 잡아주는 부분을 보다보면 어떤 코드가 좋은 코드인지 배울 수 있을 것이라 생각해서 도입하게 됬다.
Jenkins도, Sonarqube도 처음 써보기 때문에 여러모로 문제가 많았지만 어떻게어떻게 하나씩 해결하고 서버에 무사히 올려서 CI/CD 파이프라인에 통합할 수 있었다. 사실 Sonarqube 관련으로는 뭐가 고민이였냐면
- 프로젝트에 꼭 필요하지 않은 기능임
- 안그래도 단일 서버인데 Jenkins에 이어 추가로 메모리를 잡아먹음
- 가장 중요한게 주변 사람들한테 얘기해도 Sonarqube가 뭐야? 라는 반응만 돌아옴
아무도 모르는 이상한 기술을 혼자만 쓰려하는게 아닌가 싶었지만 그래도 실무에선 많이 쓰인다는 Claude 말을 믿고 도입했는데 결과는 꽤 만족스러웠다.
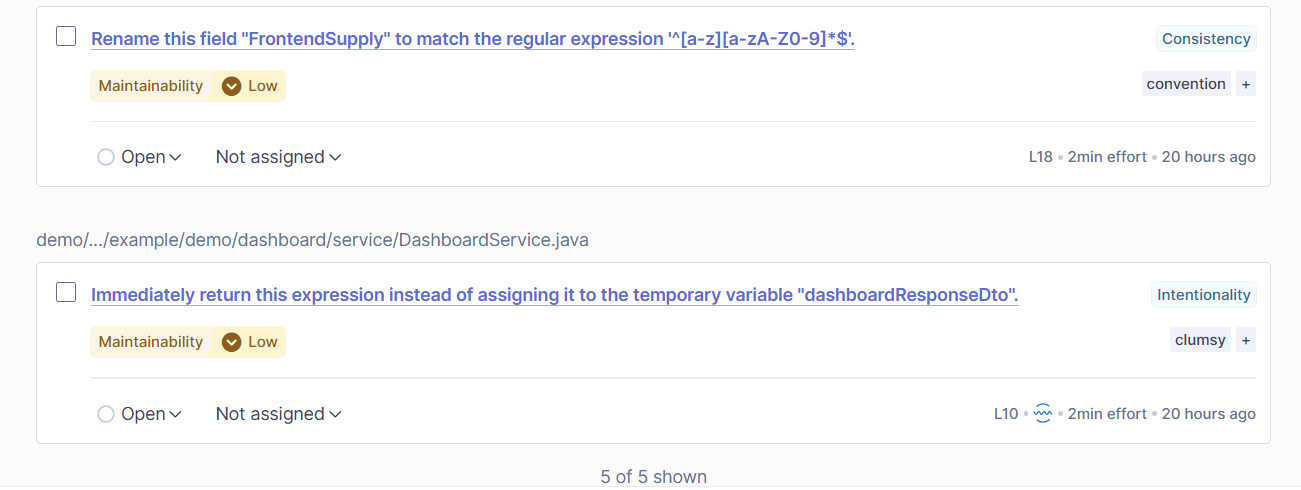
자바의 표준 문법 컨벤션에 맞지 않는 변수 이름이라던가, 바로 반환해도 되는 코드를 따로 밑에서 return 문으로 변수를 반환한다던가, 이런 부분을 하나하나 잡아주는게 신기했다. 이런 서비스를 개발할 때 미리 빠르게 도입해두면 이후의 기술 부채를 줄이는데 확실하게 도움이 되겠다는 생각이 들었다.
— 25.08.18 수정
솔직히 처음 생각했던 것처럼 쓰지는 못했다. 지속가능성에 문제가 생기는 issue들도 하나씩 수정하고, 테스트 커버리지를 목표치 이상으로 항시 유지하고, duplication을 지우는 등의 활용을 생각했지만 프로젝트가 다사다난하고 기능구현에 급급하게 돌아가다 보니 거의 방치하게 됐다.
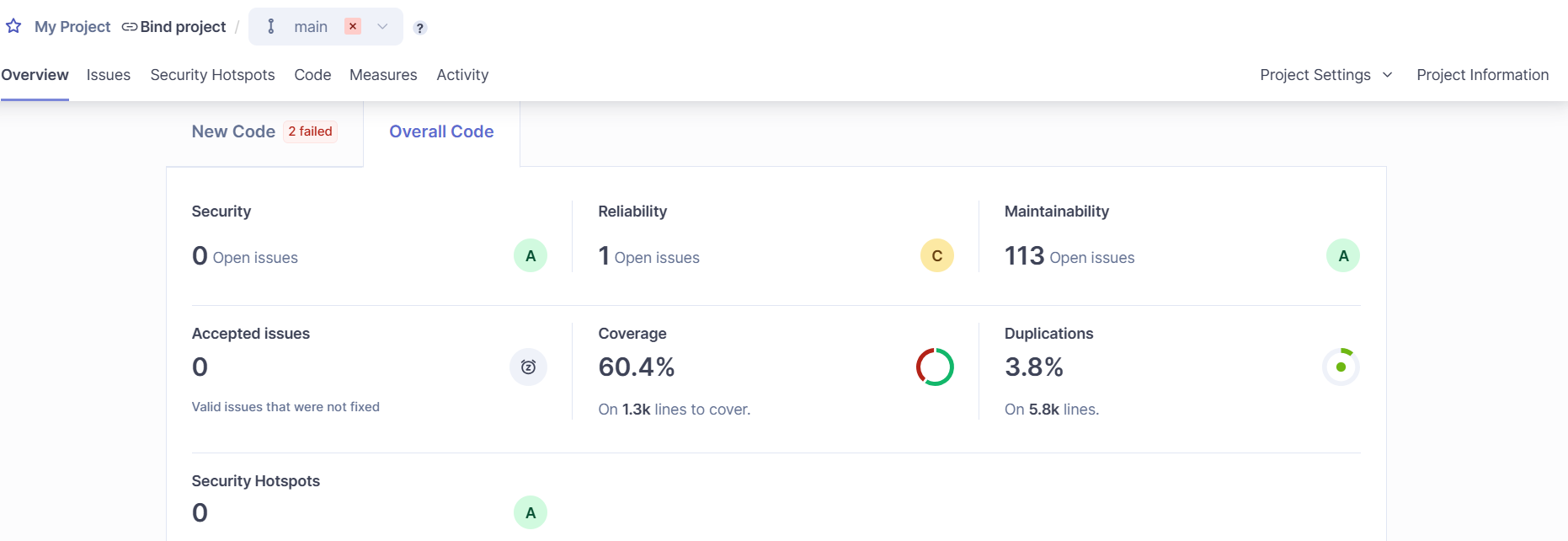
그래도 마지막에는 어느정도 커버리지를 60퍼센트 이상으로는 유지하게 되어 나름의 정량적인 성과는 거둘 수 있었다.